In the 21st century, data plays the same role that oil played in the 18th century. It drives the digital economy, proving a valuable asset for governments, businesses, and society alike. This puts unprecedented pressure on software developers to ensure the highest quality of data, thus evading inefficiencies and unlocking previously unimaginable insights.
However, when it comes to data quality management, there are no universal criteria, and each organization should choose their own set of metrics depending on the specifics of the software product they are building and the workflows this product aims to address, among other things.
The data quality problem is still ubiquitous, putting critical business processes at risk
Irrelevant or inaccurate data might significantly undermine any data-driven process, resulting in compromised decisions as well as legal and financial damages. Having awareness of the perils of unmanaged data can help you prevent them.
Have a look at how companies around the world are affected by less-than-optimal data:
- 77% of companies believe that inaccurate and incomplete data affects the bottom line.
- 6% of annual business revenue is lost because of poor-quality data.
- 40% of business initiatives fail because of insufficient data quality.
- 41% of companies think inconsistent data prevents them from maximizing ROI.
- Only 16% of companies cite a significant impact of predictive analytics.
- Bad data costs the US $3 trillion per year.
Here’s how using low-quality data affects critical business processes:
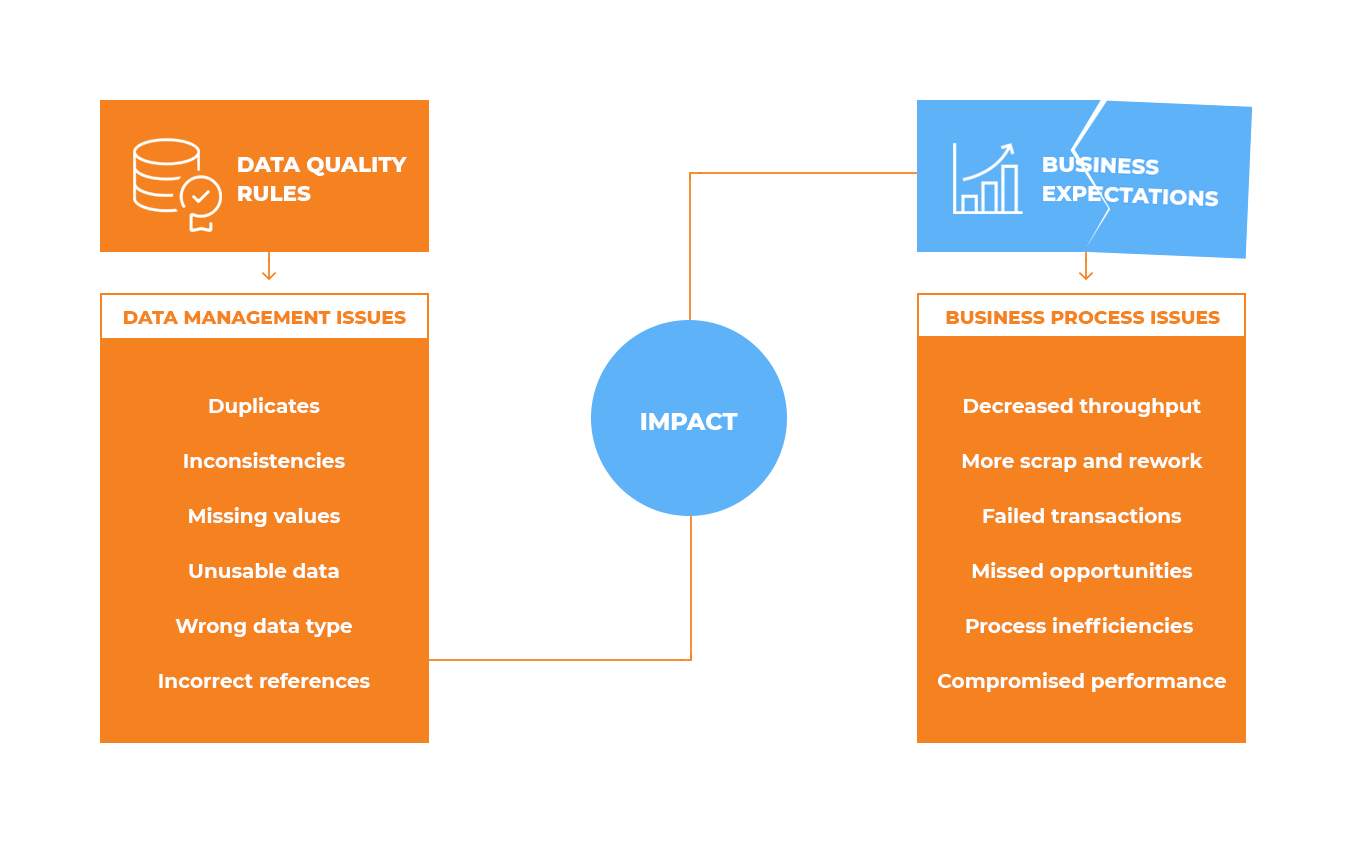 Data quality issues occur across industries. For example, in the health industry, insurance providers might be challenged by missing or invalid data, incomplete diagnostic codes, or they might fail to correctly calculate risk assurance amounts. Likewise, pharmaceutical companies relying on back-end databases may face increased customer churn as customers refuse to use new applications, not trusting the quality of data behind those apps.
Data quality issues occur across industries. For example, in the health industry, insurance providers might be challenged by missing or invalid data, incomplete diagnostic codes, or they might fail to correctly calculate risk assurance amounts. Likewise, pharmaceutical companies relying on back-end databases may face increased customer churn as customers refuse to use new applications, not trusting the quality of data behind those apps.
Financial companies depend on data integrity when it comes to payment processing. Issues such as data duplication, conflicting data values, or outdated data may cost employees time and effort and lead to transaction errors.
In software development, use of low-quality data in commercial or internal projects may ruin overall project outcomes and result in additional costs. Further, multiple project components, including data-dependent workflows, will require time-consuming reexamination by engineers.
In any case, all-round evaluation of data can help you avoid related pitfalls and fix the negative impact of your current poor-quality data. You can start with the databases used in your product as well as the metrics your development team uses to assess the quality of your applications.
If the thought of doing that all by yourself makes you uncomfortable, you can turn to a product assessment platform such as TETRA™ for help.
Benefits of taking data quality under control
If you are still uncertain about how to manage your data, have a look at the main benefits of ensuring your data is safe and sound — it might help you make up your mind.
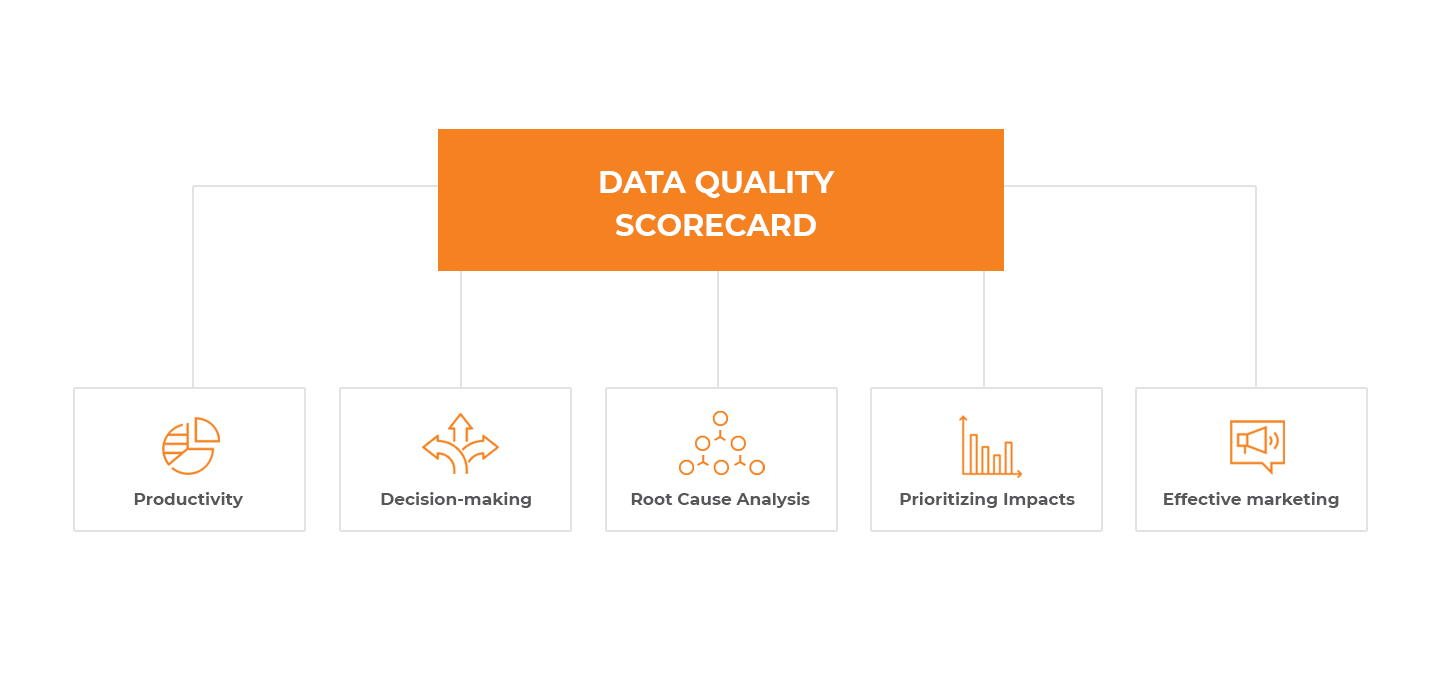
Large organizations operating massive amounts of information depend heavily on data consistency. Maintaining high-quality data helps avoid duplicate mailings, makes customer data easy to analyze and enables different departments to stay on the same page.
The paramount role of data quality can be observed in marketing. Marketers rely on personal information and statistics on demographics, customer preferences, purchasing habits, targeting and more, which is critical for the promotion of goods and services.
Verified and reliable data also helps business users and stakeholders make informed decisions.
We could go on with examples, but the unifying factor is the ability for companies to use quality data to elevate processes and take advantage of valuable opportunities.
The global standard for the evaluation of data
You must be wondering how you can estimate the quality of datasets across your organization. The international standard ISO/IEC 25012:2008 defines the quality characteristics of data. Using this standard, organizations can validate the current quality of data and detect areas for improvement.
The standard suggests 15 key characteristics to assess the quality of data used in software products and services. However, not all the elements suit every need, so it is necessary to choose the most relevant for comprehensive analysis in your organization.
Those characteristics can be split into two categories: inherent and system dependent.
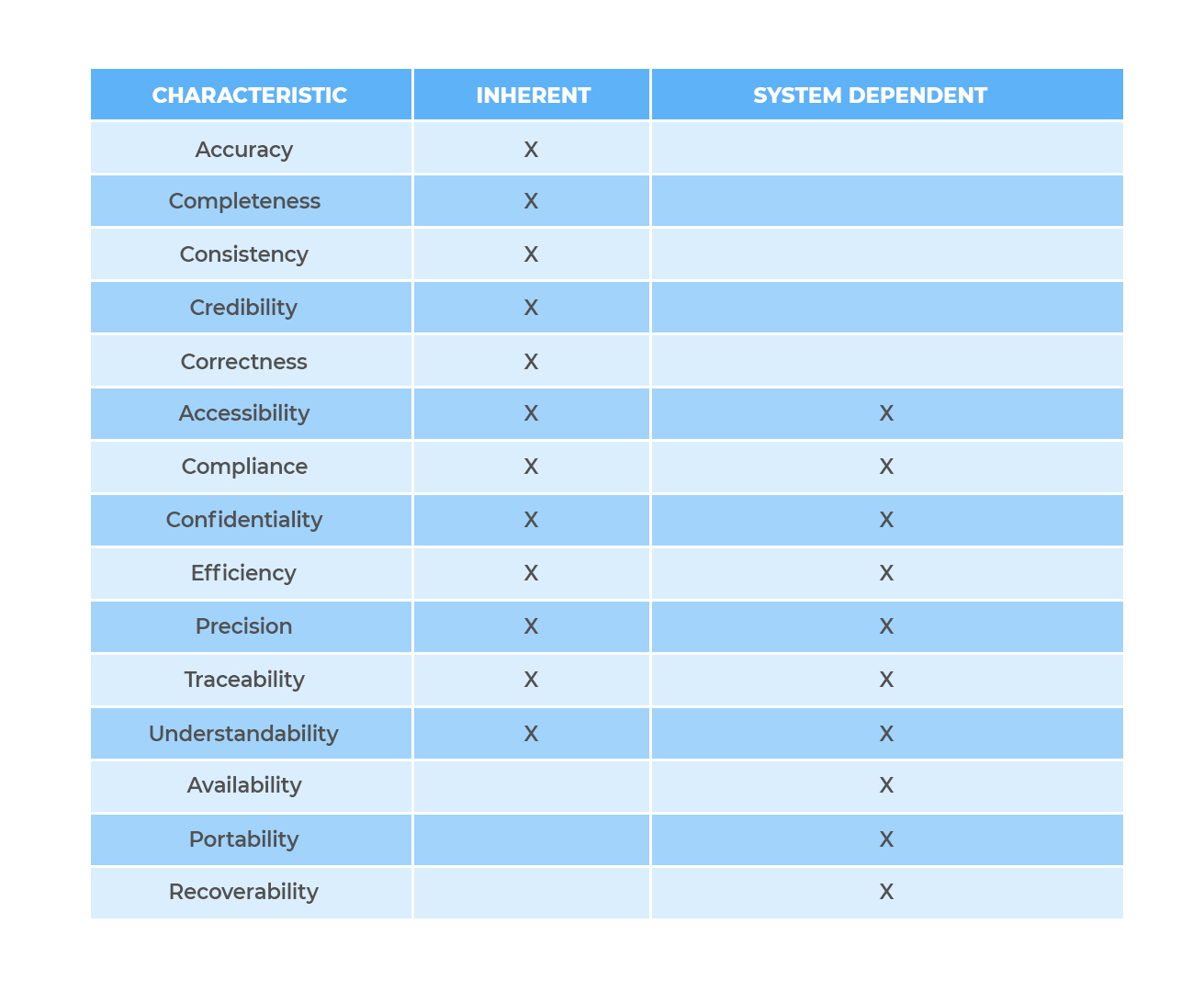 While inherent characteristics describe data itself, its types, consistency or restrictions, system-dependent characteristics define how data can be reached and maintained within a computer system and under what conditions. From this viewpoint, data depends significantly on the technological domain and capabilities of a computer system (precisely hardware), computer software as well as third-party tools and solutions.
While inherent characteristics describe data itself, its types, consistency or restrictions, system-dependent characteristics define how data can be reached and maintained within a computer system and under what conditions. From this viewpoint, data depends significantly on the technological domain and capabilities of a computer system (precisely hardware), computer software as well as third-party tools and solutions.
Depending on your industry specifics and the type of your software product, you may want to choose particular metrics while skipping others. You can also get professional consulting for your specific case and take the most suitable approach to data assessment to stay on top of the quality of your data.
Data quality management process
In our practice, follow seven steps to verify the quality of business data and maintain the quality of all datasets.
1. Define data quality metrics
Choosing which data quality metrics to monitor and which KPIs to set depends on the specifics of your product. You can follow the above-mentioned ISO/IEC product quality standard as a point of reference, choosing the most suitable set of metrics to use in your project. If you are still undecided, you can try to glean some historical insight into what might undermine your data quality, or take a trial-and-error approach.
2. Perform data profiling
You need to review all your data sources (various modules of your application) and catalog all types of data to be analyzed. Think of tables and data fields like ‘account name’ and ‘password’ as well as relevant characteristics of this data, such as whether it’s a mandatory field or not, whether it allows input of text, numbers or date, and so on. At this point, you create the full picture of how things should be.
3. Analyze selected data
At this stage, you get to check — both manually and with the help of automation tools — if the way your product captures, stores, and processes data now corresponds to the expected patterns you specified during data profiling (see the previous step). As a result, you might detect costly errors, such as missing values or values outside the required range.
4. Create the dashboard and report
You’ll need a detailed report for stakeholders to see the big picture and for tech leads to come up with an action plan based on the results of your analysis. While the former might be satisfied with a visualized dashboard for high-level insights (for instance, the overall level of data quality), the latter will need detailed information on which data requires fixing — for example, when a field that, according to the documentation, is supposed to validate input doesn’t do so, or when input is not limited as required by the documentation (for instance, users under a certain age aren’t supposed to be able to register an account in the system).
5. Perform root cause analysis
You can only do away with data pitfalls if you track down the initial problems and address them at the root level. Trace erroneous data fields and the characteristics they fail to comply with. It might be that you kicked off the project with inadequate or incomplete requirements or made mistakes in configuring the database.
6. Fix data quality issues
When you have uncovered quality issues, you need to fix them and implement solutions that can prevent further disruptions at any stage of data processing. Taking preventive measures is less costly and more efficient than dealing with low-quality data later in the project.
7. Continue regular data quality control
When you are done analyzing the product and fixing weak points, you still need to perform regular data quality testing. At least once a year, you have to verify the state of data, analyze profiling and the changing requirements to data. You should go step by step through the process described above, reveal new possible issues and fix them. The testing frequency depends on the scale and complexity of your project and the resources you have.
Conclusion
If you want to avoid some of the most notorious data issues such as inconsistency, inaccuracy, incompleteness, duplication and many others, you should set up a well-oiled quality monitoring process. In doing so, your best bet would be to follow the data quality management best practices from this article, or turn to experts who can assess the state of your data and recommend solutions to any problems they detect.
